Facilitating Hybrid Modelling in the Geosciences

Principal Research Software Engineer
ICCS - University of Cambridge
Senior Research Software Engineer
ICCS - University of Cambridge
2026-01-08
Precursors
Slides and Materials
To access links or follow on your own device these slides can be found at:
jackatkinson.net/slides
Licensing
Except where otherwise noted, these presentation materials are licensed under the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) License.

Vectors and icons by SVG Repo under CC0(1.0) or FontAwesome under SIL OFL 1.1
Introduction



Better software better reseach by the SSI
NCAR Mesa Lab painting by Julie Leidel
Weather and Climate Models
Large, complex, many-part systems.

Parameterisation
Subgrid processes are largest source of uncertainty

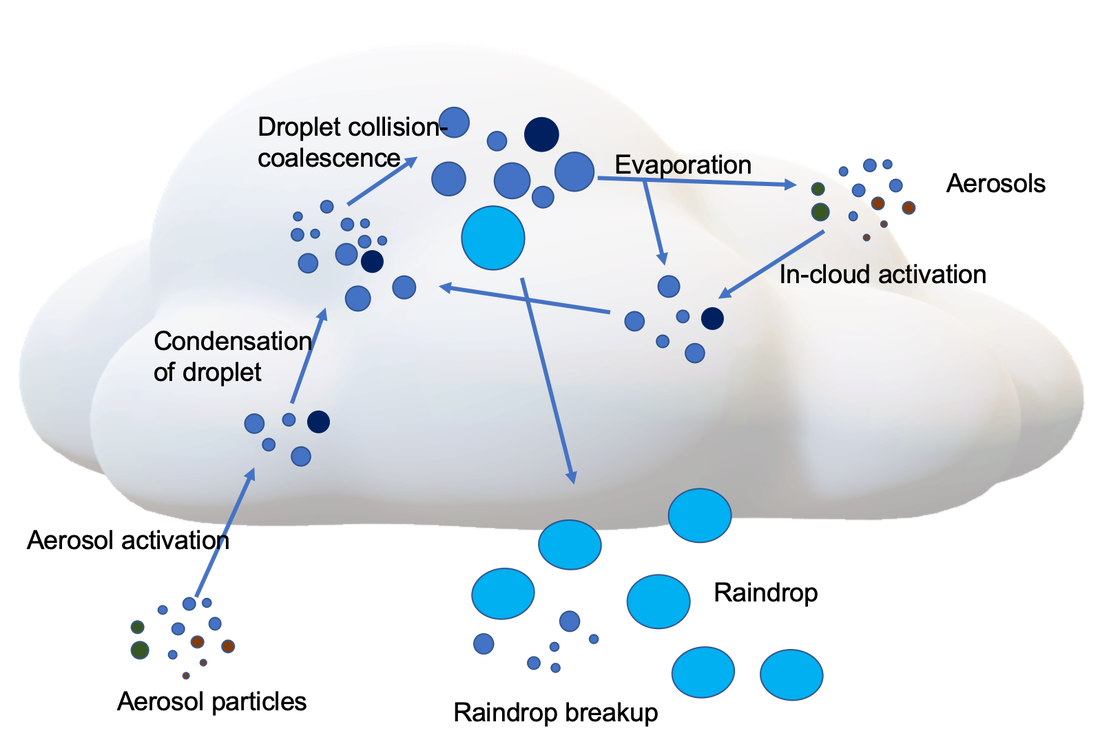
Microphysics by Sisi Chen Public Domain
Staggered grid by NOAA under Public Domain
Globe grid with box by Caltech under Fair use
Parameterisation
Subgrid processes are largest source of uncertainty
Microphysics by Sisi Chen Public Domain
Staggered grid by NOAA under Public Domain
Globe grid with box by Caltech under Fair use
Hybrid Modelling

Neural Net by 3Blue1Brown under fair dealing.
Language interoperation
Many large scientific models are written in Fortran (or C, or C++).
Much machine learning is conducted in Python.

![]()
![]()

![]()

![]()
![]()

![]()

Mathematical Bridge by cmglee used under CC BY-SA 3.0
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.”
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
Efficiency
We consider 2 types:
Computational


![]()

Developer



In research both have an effect on ‘time-to-science’.
Especially when extensive research software support is unavailable.
Highlights - Computation
- Indexing issues and associated reshape1 avoided with Torch strided accessor.
- No-copy access in memory (on CPU).

Fortran
use ftorch
implicit none
real, dimension(5), target :: in_data, out_data ! Fortran data structures
type(torch_tensor), dimension(1) :: input_tensors, output_tensors ! Set up Torch data structures
type(torch_model) :: torch_net
integer, dimension(1) :: tensor_layout = [1]
in_data = ... ! Prepare data in Fortran
! Create Torch input/output tensors from the Fortran arrays
call torch_tensor_from_array(input_tensors(1), in_data, torch_kCPU)
call torch_tensor_from_array(output_tensors(1), out_data, torch_kCPU)
call torch_model_load(torch_net, 'path/to/saved/model.pt', torch_kCPU) ! Load ML model
call torch_model_forward(torch_net, input_tensors, output_tensors) ! Infer
call further_code(out_data) ! Use output data in Fortran immediately
! Cleanup
call torch_delete(model)
call torch_delete(in_tensors)
call torch_delete(out_tensor)![]()
GPU Acceleration
Cast Tensors to GPU in Fortran:
! Load in from Torchscript
call torch_model_load(torch_net, 'path/to/saved/model.pt', torch_kCUDA, device_index=0)
! Cast Fortran data to Tensors
call torch_tensor_from_array(in_tensor(1), in_data, torch_kCUDA, device_index=0)
call torch_tensor_from_array(out_tensor(1), out_data, torch_kCPU)![]()
FTorch supports NVIDIA CUDA, ARM HIP, Intel XPU, and AppleSilicon MPS hardwares.
Use of multiple devices supported.
Effective HPC simulation requires MPI_Gather() for efficient data transfer.
Online Training & Autograd
Progress:
- Autograd and
backwards- ✓ - Overload operators - ✓
+,-,*,/,**
- Optimisers - ✓
SGD,Adam,AdamW
- Loss functions -
sumandmean
- Model interface -
\[\begin{bmatrix}f_1\\f_2\\f_3\\f_4\end{bmatrix}=\mathbf{f}(\mathbf{x};\mathbf{a})=\mathbf{a}\bullet\mathbf{x}\equiv\begin{bmatrix}a_1x_1\\a_2x_2\\a_3x_3\\a_4x_4\end{bmatrix}\]
Starting from \(\mathbf{a}=\mathbf{x}:=\begin{bmatrix}1,1,1,1\end{bmatrix}^T\), optimise \(\mathbf{a}\) such that \(\mathbf{f}(\mathbf{x};\mathbf{a})=\begin{bmatrix}1,2,3,4\end{bmatrix}^T\).

In both cases we achieve \(\mathbf{f}(\mathbf{x};\mathbf{a})=\begin{bmatrix}1,2,3,4\end{bmatrix}^T\).
Further Information
FTorch is published in JOSS!
![]()
Atkinson et al. (2025)
FTorch: a library for coupling PyTorch models to Fortran.
Journal of Open Source Software, 10(107), 7602,
doi.org/10.21105/joss.07602
Online documentation is available at: cambridge-iccs.github.io/FTorch
In addition to the comprehensive examples in the FTorch repository we provide an online workshop at /Cambridge-ICCS/FTorch-workshop
ICON - Causality
- Icosahedral Nonhydrostatic Weather and Climate Model
- Developed by DKRZ (Deutsches Klimarechenzentrum)
- Used by the DWD and Meteo-Swiss
- Interpretable multiscale Machine Learning-Based Parameterizations of Convection for ICON (Heuer et al. 2024)1
- Train U-Net convection scheme on high-res simulation
- Deploy in ICON via FTorch coupling
- Evaluate physical realism (causality) using SHAP values
- Online stability improved when non-causal relations are eliminated from the net

![]()
ICON - Multiple Parameterisations
Work led by Julien Savre at DLR
- Closely afifliated fork of ICON
- Multiple ML components in one model
- Common FTorch interface
- A focus on running on GPU
- Implemented without ICCS involvement
![]()
CESM - Bias Correction
Work by Will Chapman of NCAR/M2LInES
As representations of physics models have inherent, sometimes systematic, biases.
Run CESM for 9 years relaxing hourly to ERA5 observation (data assimilation)
Train CNN to predict anomaly increment at each level
- targeting just the MJO region
- targeting globally
Apply online as part of predictive runs


CESM - Non-locality
- Parameterisations often column-based
- computationally efficient
- localised
- Data driven parameterisation of velocity fluxes from gravity waves.
- Trained on ERA5
- Column and Global UNet models trained.
- Implemented online in CAM7
- Some challenges from non-locality remain

UKCA - Online
- Chemistry model used in UKESM and Met Office UM
- 85-200 trackers with 300-700 interactions
- 25% of the UM runtime
- Solver is 40% of UKCA runtime (10% UM)

UKCA Flame Graph by Luke Abraham used with permission.
Data Layout/Location
- Data Layout
- Columns vs. slices
- Choose an ML method for inference data
- e.g. CNNs want structured grids
Regridding will introduce overheads
Global methods are going to introduce MPI overheads
GPU data transfer is going to introduce overheads

Know your host model
Preprocessing and training a net offline is not the only goal
Think about online inference from the start
- Is it in memory
- Is it chunked
- Load balancing!
- Is the training grid the same as model
Loading weights is expensive - do it as little as possible cf. Looping Example

Software architecture for ML parameterisations
The parameterisation:
- Pure neural net core
- Easily swapped out as new nets trained or architecture changed
- Physics layer
- Handles physical constraints and non-NN aspects of parameterisation
e.g. Conservation laws.
- Handles physical constraints and non-NN aspects of parameterisation
- Provided with a clear API of expected:
- variables, units, and grid/resolution
- appropriate parameter ranges

Software architecture for ML parameterisations
The coupling:
- Interface layer
- Passes data from/to host model/parameterisation
- Handles physical variable transformations and regridding
- Handles generalisation

Net “Architecture”
Operate a principle of separation between physical model and net.
Concatenation and Normalisation
- part of the NN, not part of the physics
The alternative is re-writing code to perform this in the physical model
- taking time,
- reducing reproducibility
- adding complexity.
Thanks for Listening
Get in touch:
Thanks to Joe Wallwork, Tom Meltzer, Elliott Kasoar,
Niccolò Zanotti and the rest of the FTorch team.
The ICCS received support from 
FTorch has been supported by ![]()

