Introduction to Machine Learning with PyTorch
NCAS & ICCS Summer Schools 2023
Jack Atkinson 
ICCS/Cambridge
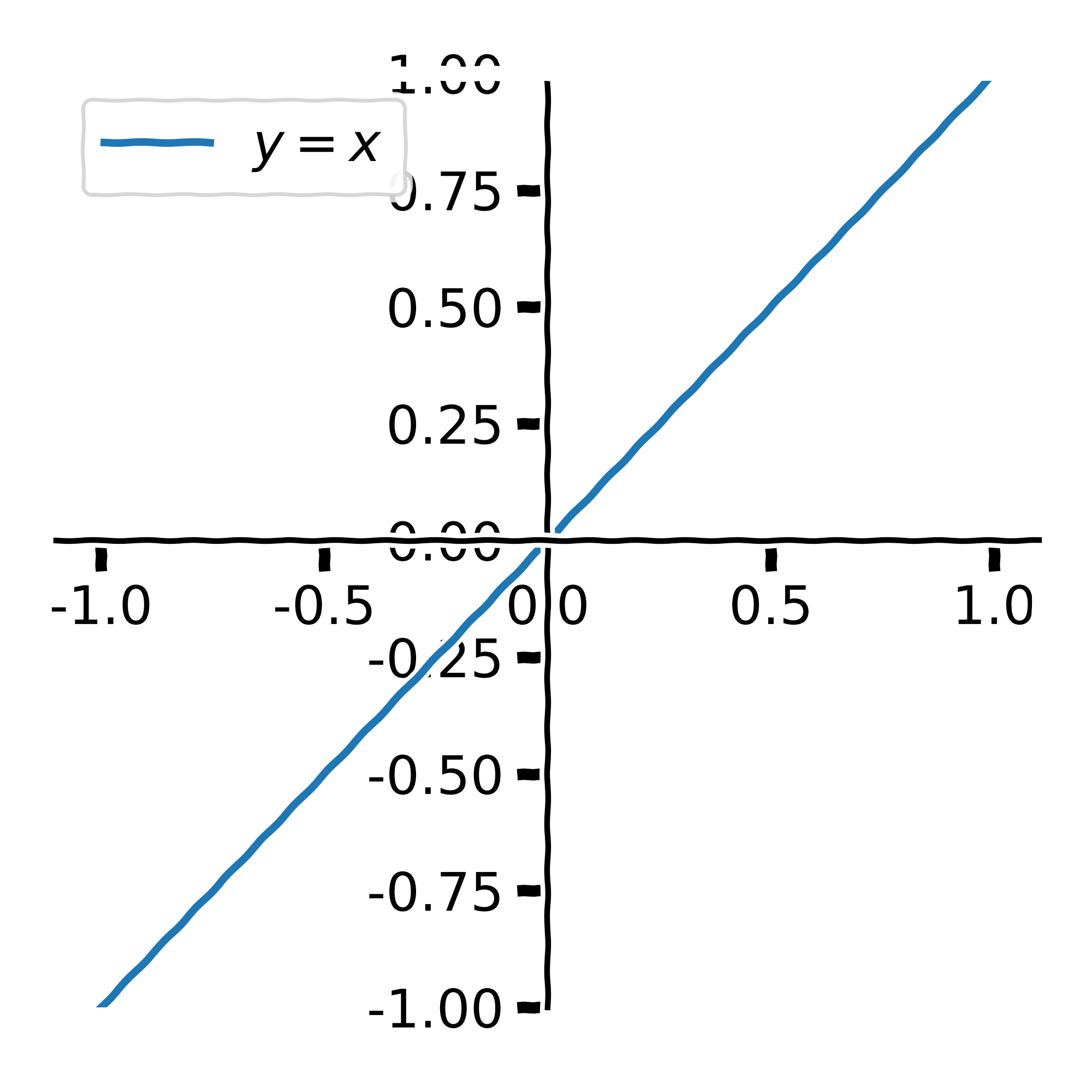
Fitting a straight line with SGD II
- Answer—a function’s derivative gives a vector which points in the direction of steepest ascent.
- Consider
\[y = x\]
\[\frac{dy}{dx} = 1\]
- What is the direction of steepest descent?
\[-\frac{dy}{dx}\]
Fully-connected neural networks
- The simplest neural networks commonly used are generally called fully-connected nerual nets, dense networks, multi-layer perceptrons, or artifical neural networks (ANNs).
- We map between the features at consecutive layers through matrix multiplication and the application of some non-linear activation function.
\[a_{l+1} = \sigma \left( W_{l}a_{l} + b_{l} \right)\]
- For common choices of activation functions, see the PyTorch docs.

Image source: 3Blue1Brown
Penguins!

Image source: Palmer Penguins by Alison Horst
Convolutional neural networks (CNNs): why?
Advantages over simple ANNs:
- They require far fewer parameters per layer.
- The forward pass of a conv layer involves running a filter of fixed size over the inputs.
- The number of parameters per layer does not depend on the input size.
- They are a much more natural choice of function for image-like data:

Image source: Machine Learning Mastery
What is a (1D) convolutional layer?
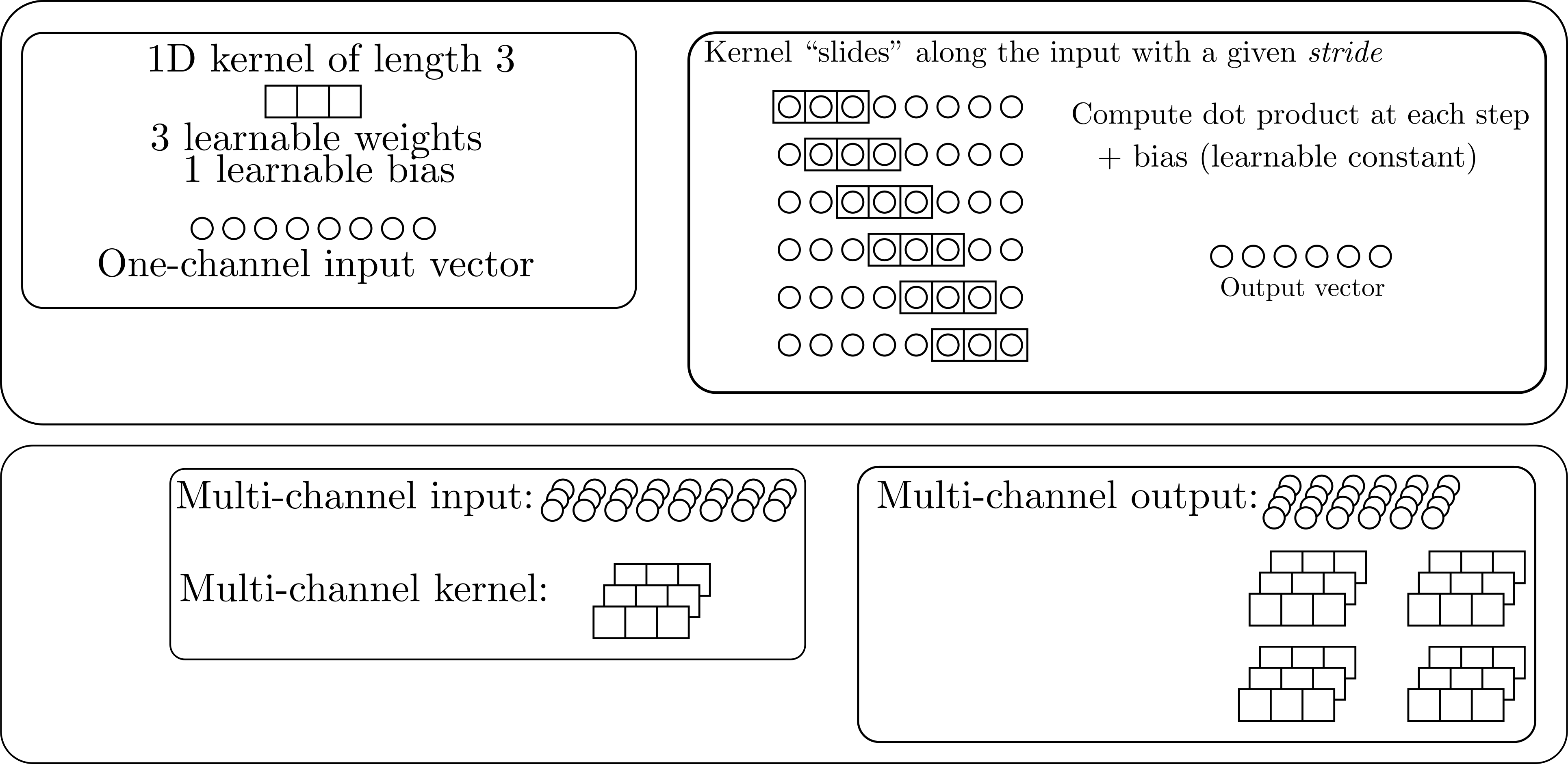
See the torch.nn.Conv1d docs
2D convolutional layer
- Same idea as in on dimension, but in two (funnily enough).
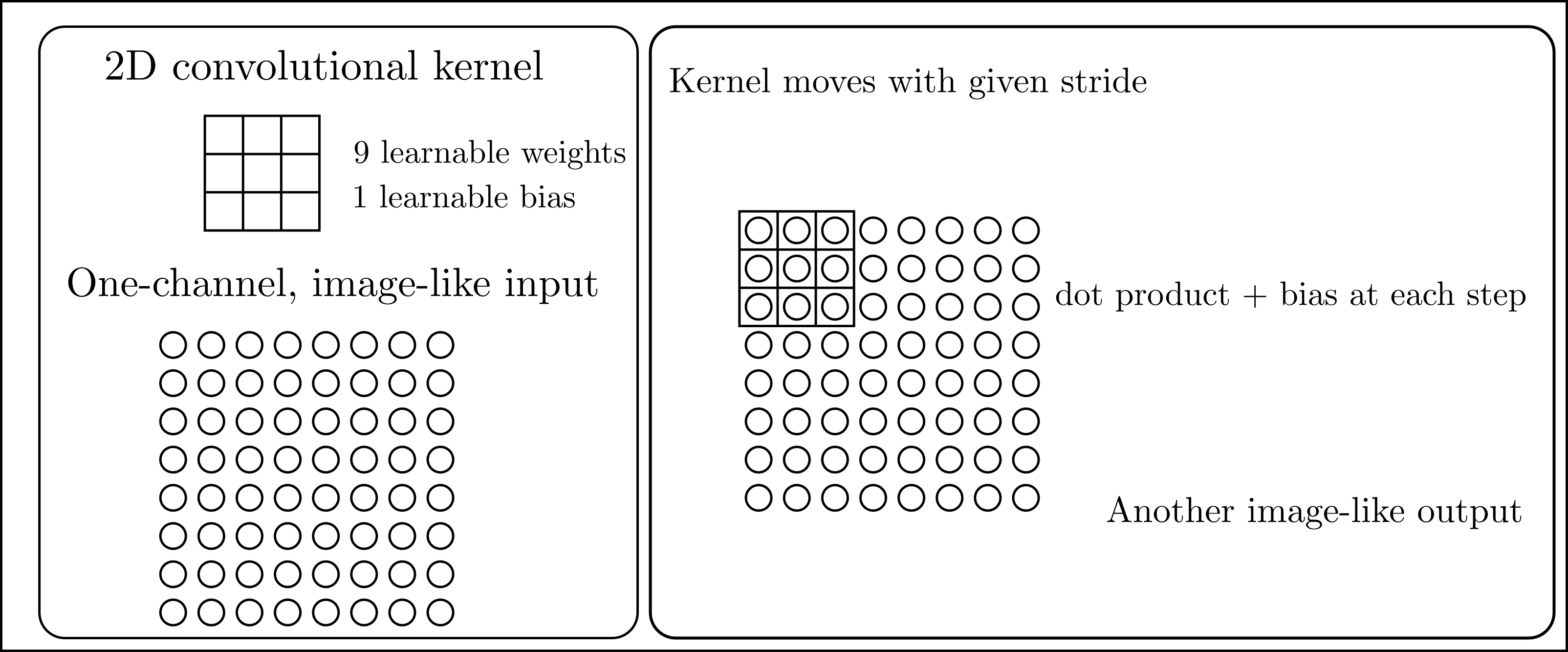
- Everthing else proceeds in the same way as with the 1D case.
- See the
torch.nn.Conv2ddocs. - As with Linear layers, Conv2d layers also have non-linear activations applied to them.
Typical CNN overview
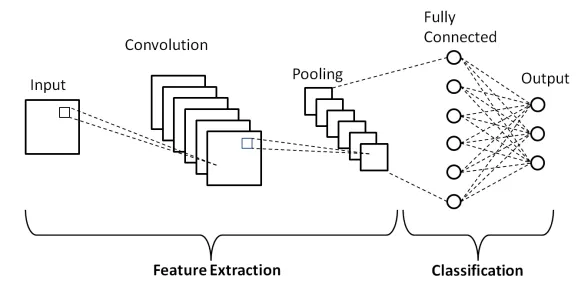
- Series of conv layers extract features from the inputs.
- Often called an encoder.
- Adaptive pooling layer:
- Image-like objects \(\to\) vectors.
- Standardises size.
torch.nn.AdaptiveAvgPool2dtorch.nn.AdaptiveMaxPool2d
- Classification (or regression) head.
- For common CNN architectures see
torchvision.modelsdocs.
Exercise 1 – classification
MNIST hand-written digits.

- In this exercise we’ll train a CNN to classify hand-written digits in the MNIST dataset.
- See the MNIST database wiki for more details.
Image source: npmjs.com
Contact
For more information we can be reached at:
Jack Atkinson
You can also contact the ICCS, make a resource allocation request, or visit us at the Summer School RSE Helpdesk.
![]()