FTorch - facilitating Hybrid Modelling

Senior Research Software Engineer
ICCS - University of Cambridge
2025-07-02
Precursors
Slides and Materials
To access links or follow on your own device these slides can be found at:
jackatkinson.net/slides
Licensing
Except where otherwise noted, these presentation materials are licensed under the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) License.

Vectors and icons by SVG Repo under CC0(1.0) or FontAwesome under SIL OFL 1.1
Weather and Climate Models
Large, complex, many-part systems.

Parameteristion
Subgrid processes are largest source of uncertainty

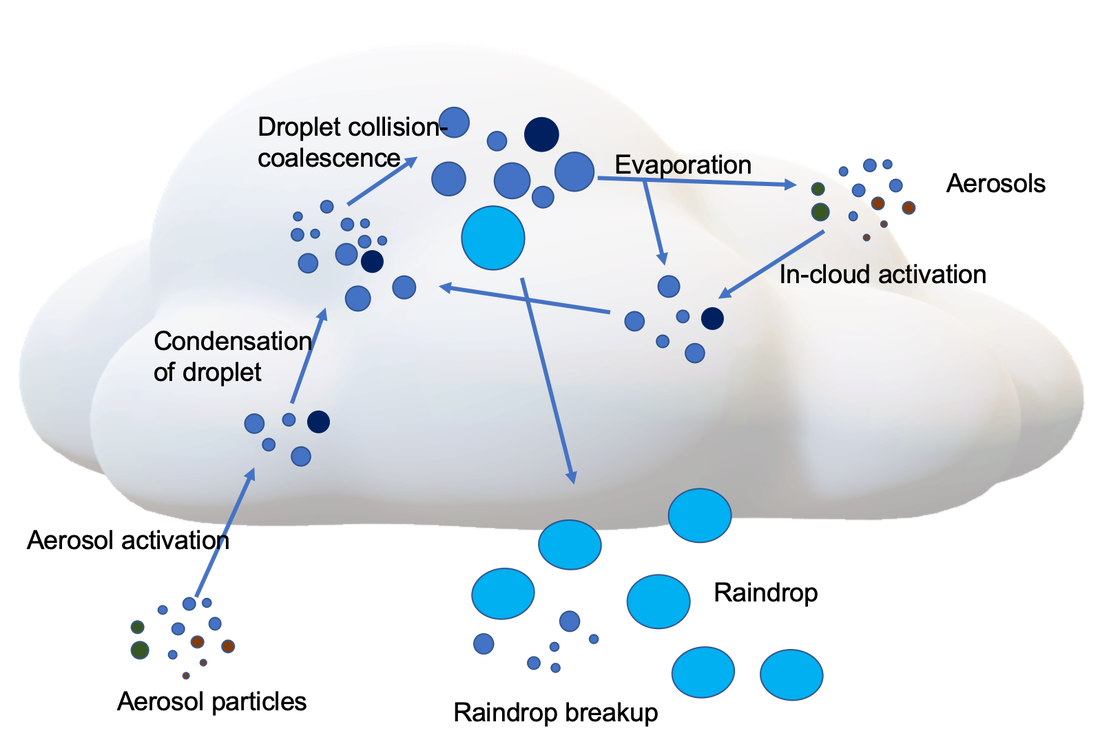
Microphysics by Sisi Chen Public Domain
Staggered grid by NOAA under Public Domain
Globe grid with box by Caltech under Fair use
Parameteristion
Subgrid processes are largest source of uncertainty
Microphysics by Sisi Chen Public Domain
Staggered grid by NOAA under Public Domain
Globe grid with box by Caltech under Fair use
Machine Learning in Science

Neural Net by 3Blue1Brown under fair dealing.
Pikachu © The Pokemon Company, used under fair dealing.
Language interoperation
Many large scientific models are written in Fortran (or C, or C++).
Much machine learning is conducted in Python.

![]()
![]()

![]()

![]()
![]()

![]()

Mathematical Bridge by cmglee used under CC BY-SA 3.0
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.”
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
Efficiency
We consider 2 types:
Computational


![]()

Developer



At the academic end of research both have an equal effect on ‘time-to-science’.
Especially when extensive research software support is unavailable.
Approach
![]()
![]()
![]()
![]()

![]()
Python
env
Python
runtime
![]()
xkcd #1987 by Randall Munroe, used under CC BY-NC 2.5
![]()
Highlights - Computation
- No-copy access in memory (on CPU).
- Indexing issues and associated reshape1 avoided with Torch strided accessor.

Find it on :
Model - Saving from Python
import torch
import torchvision
# Load pre-trained model and put in eval mode
model = torchvision.models.resnet18(weights="IMAGENET1K_V1")
model.eval()
# Create dummmy input
dummy_input = torch.ones(1, 3, 224, 224)
# Trace model and save
traced_model = torch.jit.trace(model, dummy_input)
frozen_model = torch.jit.freeze(traced_model)
frozen_model.save("/path/to/saved_model.pt")![]()
TorchScript
- Statically typed subset of Python
- Read by the Torch C++ interface (or any Torch API)
- Produces intermediate representation/graph of NN
- Including weights and biases
- Trace for simple models, script also available
GPU Acceleration
Cast Tensors to GPU in Fortran:
! Load in from Torchscript
call torch_model_load(torch_net, 'path/to/saved/model.pt', torch_kCUDA, device_index=0)
! Cast Fortran data to Tensors
call torch_tensor_from_array(in_tensor(1), in_data, tensor_layout, torch_kCUDA, device_index=0)
call torch_tensor_from_array(out_tensor(1), out_data, tensor_layout, torch_kCPU)![]()
Effective HPC simulation requires MPI_Gather() for efficient data transfer.
ICON
- Icosahedral Nonhydrostatic Weather and Climate Model
- Developed by DKRZ (Deutsches Klimarechenzentrum)
- Used by the DWD and Meteo-Swiss
- Interpretable multiscale Machine Learning-Based Parameterizations of Convection for ICON (Heuer et al. 2023)1
- Train U-Net convection scheme on high-res simulation
- Deploy in ICON via FTorch coupling
- Evaluate physical realism (causality) using SHAP values
- Online stability improved when non-causal relations are eliminated from the net

![]()
CESM coupling
- The Community Earth System Model
- Part of CMIP (Coupled Model Intercomparison Project)
- Make it easy for users
- FTorch integrated into the build system (CIME)
libtorchis included on the software stack on Derecho- Improves reproducibility

Derecho by NCAR
CESM - Bias Correction
Work by Will Chapman of NCAR/M2LInES
As representations of physics models have inherent, sometimes systematic, biases.
Run CESM for 9 years relaxing hourly to ERA5 observation (data assimilation)
Train CNN to predict anomaly increment at each level
- targeting just the MJO region
- targeting globally
Apply online as part of predictive runs


- Low hanging fruit: Don’t load model (with all its weights) at every timestep!
Putting it together - running an optimiser in FTorch

losses
In both cases we achieve \(\mathbf{f}(\mathbf{x};\mathbf{a})=\begin{bmatrix}1,2,3,4\end{bmatrix}^T\).
Thanks for Listening
Get in touch:
![]()
The ICCS received support from 
Benchmarking
Following the comparisons and MiMA experiments we performed detailed benchmarking to examine the library performance.




