%%{init: {'theme': 'dark',
'gitGraph': {'rotateCommitLabel': true},
'themeVariables': {
'commitLabelBackground': '#bbbbbb',
'commitLabelColor': '#ffffff'
} } }%%
gitGraph
commit id: "1-ad4e"
commit id: "4-ff6b"
commit id: "0-fd7f"
commit id: "1-2y4f Improve README"
commit id: "4-664e Add a LICENSE file"
commit id: "6-d3et Add a .gitignore from template"
git for Scientific Software Development
Jack Atkinson 
Senior Research Software Engineer
ICCS - University of Cambridge
2024-02-27
Precursors
Slides and Materials
To access links or follow on your own device these slides can be found at:
https://jackatkinson.net/slides
All materials are available at:
Licensing
Except where otherwise noted, these presentation materials are licensed under the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) License.

Precursors
- Be nice (Python code of conduct)
- Ask questions whenever they arise.
- Someone else is probably wondering the same thing.
- I will make mistakes.
- Not all of them will be intentional.
whoami
Research background in fluid mechanics and atmosphere:
- Numerics and fluid mechanics in Engineering,
- Cloud microphysics & volcanic plumes in Geography,
- Radiation belts and satellite data at BAS.
Now a Research Software Engineer (RSE) at the Institute of Computing for Climate Science (ICCS) working with various groups and projects.
I have a particular interest in climate model design and parameterisation.
This talk can be summarised as “things I wish I’d known sooner.”


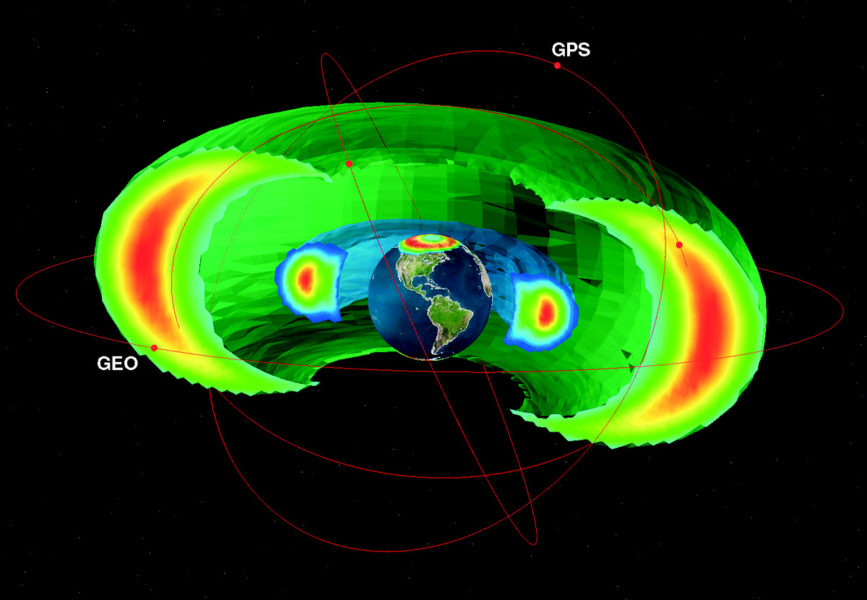
What is Research Software?
Major Computational Programs


Data processing

Experiment support



Bathymetry by NOAA under public domain
CTD Bottles by WHOI under public domain
Keeling Curve by Scripps under public domain
Climate simulation by Los Alamos National Laboratory under CC BY-NC-ND
Dawn HPC by Joe Bishop with permission
Why does this matter?
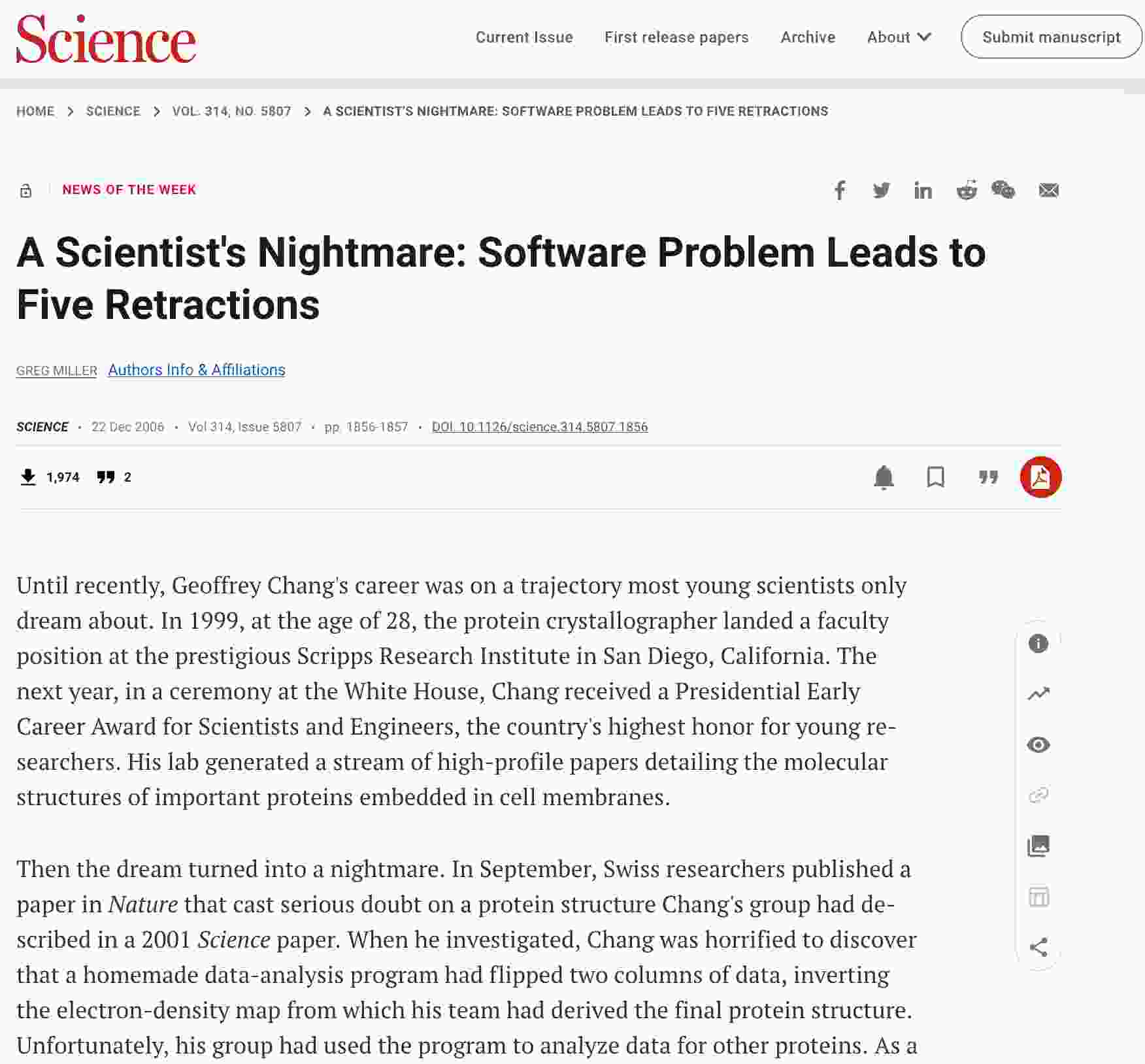
Why does this matter?
More widely than publishing papers, code is used in control and decision making:
- Weather forecasting
- Climate policy
- Disease modelling (e.g. Covid)
- Satellites and spacecraft1
- Medical Equipment
Your code (or its derivatives) may well move from research to operational one day.

Margaret Hamilton and the Apollo XI by NASA under public domain
Why does this matter?1
def calc_p(n,t):
return n*1.380649e-23*t
data = np.genfromtxt("mydata.csv")
p = calc_p(data[0,:],data[1,:]+273.15)
print(np.sum(p)/len(p))What does this code do?
# Boltzmann Constant and 0 Kelvin
Kb = 1.380649e-23
T0 = 273.15
def calc_pres(n, t):
"""
Calculate pressure using ideal gas law p = nkT
Parameters:
n : array of number densities of molecules [N m-3]
t : array of temperatures in [K]
Returns:
array of pressures [Pa]
"""
return n * Kb * t
# Read in data from file and convert T from [oC] to [K]
data = np.genfromtxt("mydata.csv")
n = data[0, :]
temp = data[1, :] + T0
# Calculate pressure, average, and print
pres = calc_pres(n, temp)
pres_av = np.sum(pres) / len(pres)
print(pres_av)git 101
What is git
git is a version control system developed by Linus Torvalds1.
It tracks changes made to files over time.

Installation and setup
Git comes preinstalled on most Linux distributions and macOS.
You can check it is on your system by running which git.
If you are on Windows, or do not have git, check the git docs1 or the GitHub guide to installing git. https://github.com/git-guides/install-git
Setting up a new git repository is beyond the scope of this talk but involves using the
git --init command.
We will assume that you have created a repository using an online hosting service (GitLab, GitHub etc.) that provides a nice UI wrapper around the process.
How does it work?
A mental model:
- Each time you
commitwork git stores it as adiff.- This shows specific lines of a file and how they changed (
+/-). - This is what you see with the
git diffcommand.
- This shows specific lines of a file and how they changed (
diffs are stored in atree.- By applying each
diffone at a time we can reconstruct files. - We do not need to do this in order
see cherry-picking and merge conflicts…
- By applying each
How does it work?
diff --git a/mycode/functions.py b/mycode/functions.py
index b784b07..d08024a 100644
--- a/mycode/functions.py
+++ b/mycode/functions.py
@@ -340,11 +341,10 @@ def rootfind_score(
fpre = fcur
if abs(scur) > delta:
xcur += scur
+ elif sbis > 0:
+ xcur += delta
else:
- if sbis > 0:
- xcur += delta
- else:
- xcur -= delta
+ xcur -= delta
fcur = f_root(xcur, score, rnd)
val = xcurHow does it work?
Actually:
- Each time you
commitwork git creates asnapshot- Contains the commit message and a hash to a
tree.
- Contains the commit message and a hash to a
- The
treeis a list of files in the repo at this commit.- In reality it is a
treeoftrees for efficiency! - The roots of the tree are
packed files at time of commit.
- In reality it is a
packed files are efficiently compressed.- And may use
deltas which are a bit likediffs.
- And may use
- By tracing the tree and then un
packing we can reconstruct the repo at a state in time given by the commit hash.
Evans (2024)
The basic commands
git clone <repo> [<dir>]- Clone a repository into a new directory
$ git clone git@github.com:jatkinson1000/git-for-science.github git4sci
Cloning into 'git4sci'...
remote: Enumerating objects: 42, done.
remote: Counting objects: 100% (42/42), done.
remote: Compressing objects: 100% (39/39), done.
remote: Total 42 (delta 26), reused 31 (delta 15), pack-reused 0
Receiving objects: 100% (42/42), 69.62 MiB | 5.64 MiB/s, done.
Resolving deltas: 100% (26/26), done.
$
$ cd git4sci/
$
$ echo "This is a new file." > newfile.txt
$The basic commands
git clone <repo> [<dir>]- Clone a repository into a new directory
git status- Check the state of the directory
git add <filepath>- Update the index with any changes
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
newfile.txt
no changes added to commit (use "git add" and/or "git commit -a")
$
$ git add newfile.txt
$
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: newfile.txt
$The basic commands
git clone <repo> [<dir>]- Clone a repository into a new directory
git status- Check the state of the directory
git add <filepath>- Update the index with any changes
git commitgit commit -m <message>- Commit to record changes in the index
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: newfile.txt
$
$ git commit -m "Add newfile with placeholder text."
1 file changed, 1 insertion(+)
create mode 100644 newfile.txt
$
$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
no changes added to commit (use "git add" and/or "git commit -a")
$The basic commands
git clone <repo> [<dir>]- Clone a repository into a new directory
git status- Check the state of the directory
git add <filepath>- Update the index with any changes
git commitgit commit -m <message>- Commit to record changes in the index
git push <remote> <branch>- Send your locally committed changes to the remote repo
$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
no changes added to commit (use "git add" and/or "git commit -a")
$
$ git push origin main
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Delta compression using up to 8 threads
Compressing objects: 100% (8/8), done.
Writing objects: 100% (8/8), 1.89 KiB | 1.89 MiB/s, done.
Total 8 (delta 7), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (7/7), completed with 7 local objects.
remote:
To github.com:jatkinson1000/git-for-science.git
7647d3a..7ab12ff main -> main
$The git atlas
Locations
- Workspace
- Staging area or index
- Local repo
- Remote repo
- Stash
These (and more) can be explored in Andrew Peterson’s Interactive git cheat sheet
A Warning

How does this help in science?
Exercise
You are doing some work on pendula and your colleague says they have written some code that solves the equations and they can share with you.
This is made easy by the fact that it is on git!
Let’s see how we get on…
Go to the workshop repository:
If you have an account then fork the repository and clone your fork.
If you do not have an account clone my repository.
Take a look around, how useful is this?1
Repository Files
README
- A file in the main directory of your repository
- The entry point for new users.
- Helps to ensure your code is used properly
- Today encouraged to be written in Markdown as
README.md
README
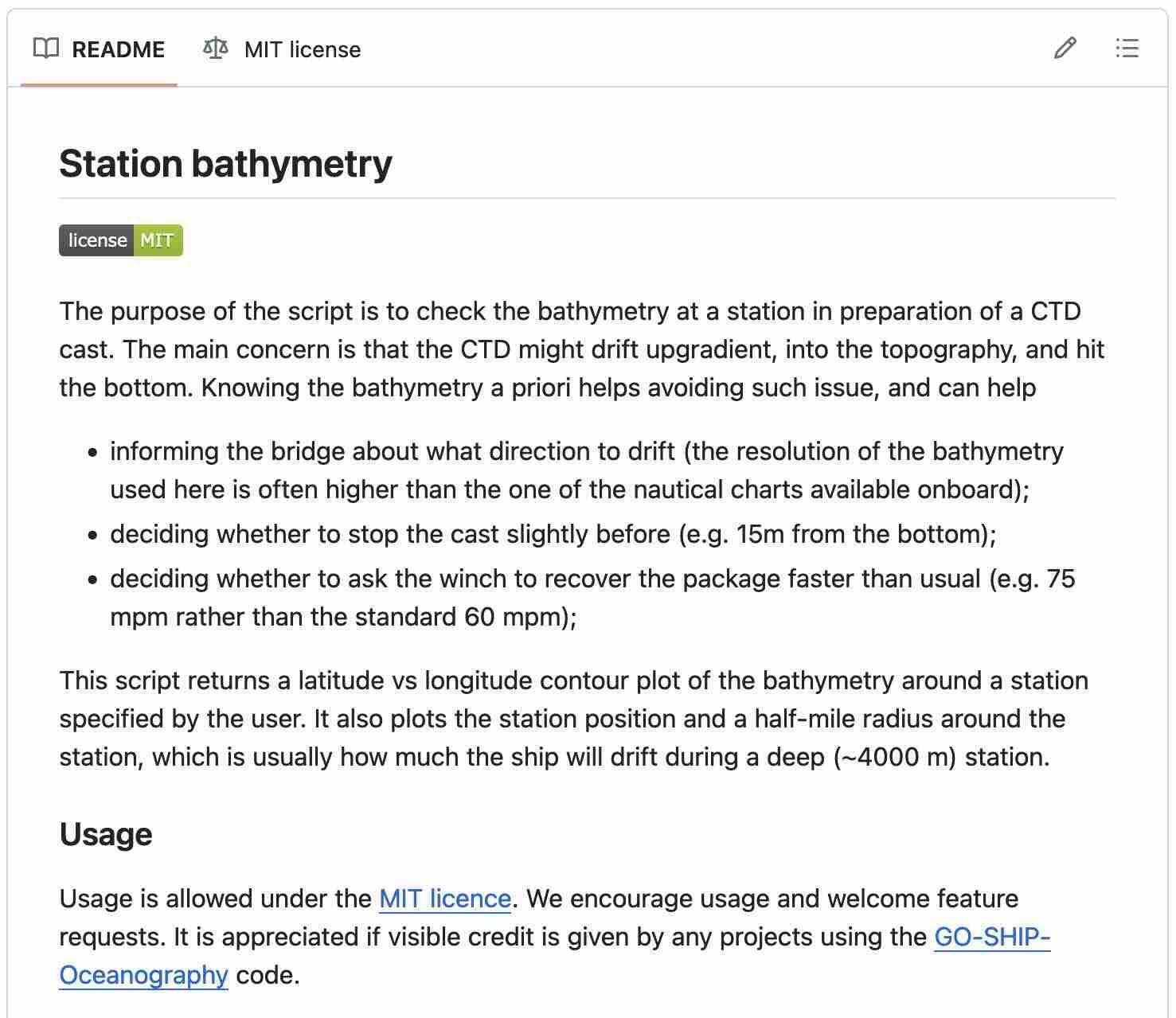
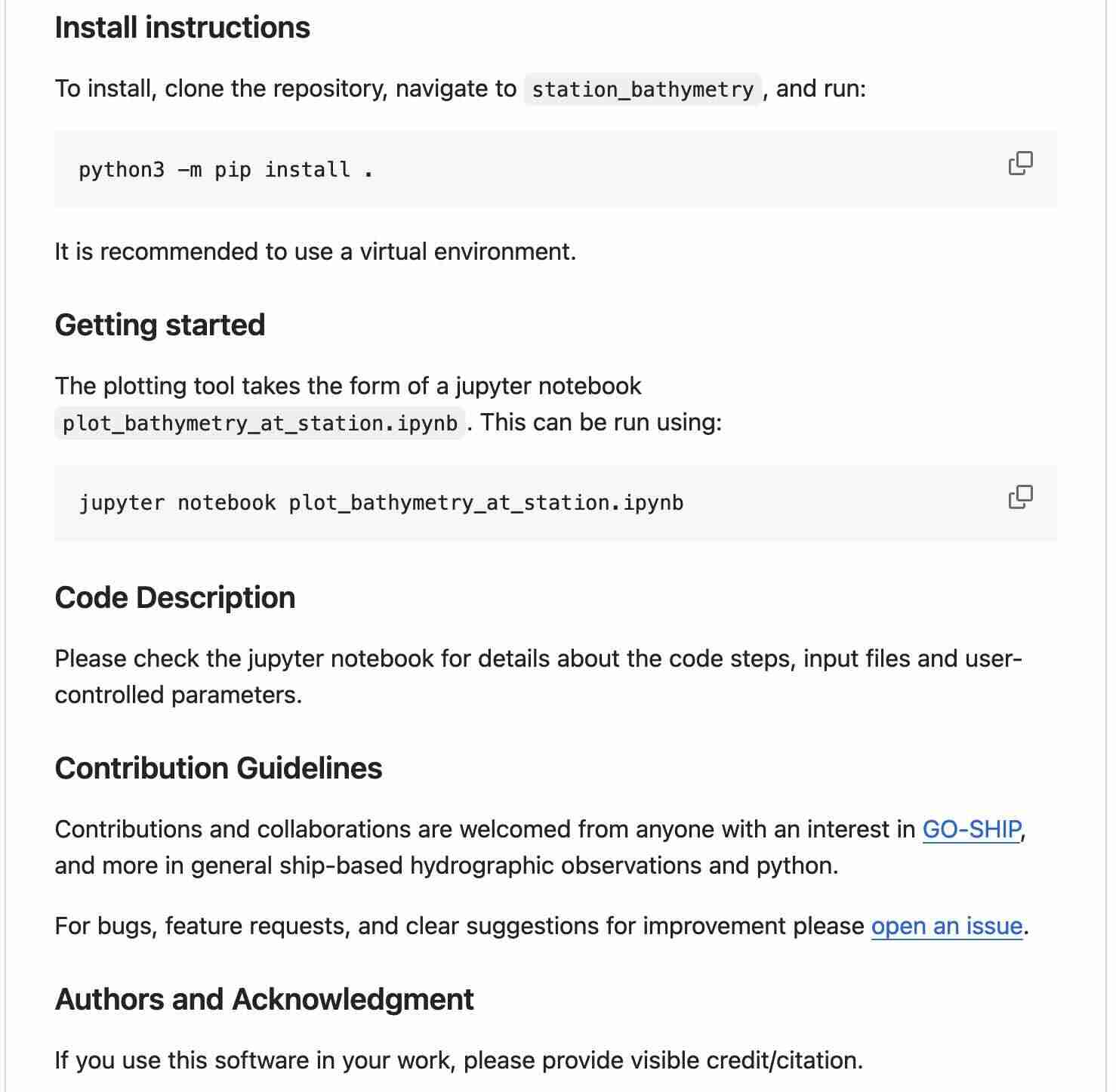
README
Essential
- Name
- Short summary
- Install instructions
- Usage/getting-started instructions
- Information about contributing
- Authors and Acknowledgment
- License information
Nice to have:
- References to key papers/materials
- Badges
- Examples
- Link to docs
- List of users
- FAQ
- See readme.so/ for a longer list
makeareadme.com and readme.so are great tools to help.
Add as soon as you can in a project and update as you go along.
Exercise - README
How can we improve the README in the pyndulum code?
License
All public codes should have a license attached!
LICENSEfile in the main directory- Protect ownership
- Limit liability
- Clarify what can be done with the code
- Public Domain, Permissive, Copyleft
The right selection may depend on your organisation and/or funder.
See choosealicense.com for more information.
GitHub and GitLab contain helpers to create popular licenses.
Exercise - License
Add a license to our pyndulum code.
If you use a helper feature to do this online, don’t forget to
git pull <repo> <branch>
to get this locally before you make further changes.
.gitignore
It is a good idea to add a .gitignore file to your projects.
- A list of file patterns that will be skipped over by git.
- Makes it easier for us to see through to what is important.
- Used for:
- junk that shouldn’t be in there - the infamous
.DS_store - build files -
mycode.oormymodule.modetc. - large files -
50_year_run.ncormy_thesis.pdfetc. - keeping sensitive information out of public1
- junk that shouldn’t be in there - the infamous
Again, GitHub and GitLab contain helpers and templates to create .gitignore.
Exercise - .gitignore
Add a .gitignore to the pyndulum code?
Again, if you use a helper feature to do this online, don’t forget to git pull.
Workflow
Issues
Both GitHub and GitLab have methods for tacking issues.
These are useful for keeping track of work.
Issues should be opened on the main project, not individual forks.
Example issue log on GitHub: jatkinson1000/archeryutils
NOTE: This is part of GitHub/GitLab, NOT the git repository.
They will not be kept if you move the project elsewhere and do not appear on your local system.
Exercise - Issues
It would be nice if we could add functions to calculate pendulum length from desired period and energy.
If part of the workshop, open an issue for these on the the repository.
Branches
So far we have been using origin main in everything we do.
origin is the location of our online repository
So far our commits look something like this:
But what if:
- Someone else is adding things in the same files as us.
- We are working on two different aspects/features of the project.
- We find a bug and need to fix it.
Branches
Branches help with all of the aforementioned situations, but are a sensible way to organise your work even if you are the only contributor.
%%{init: {'theme': 'dark',
'gitGraph': {'rotateCommitLabel': true},
'themeVariables': {
'commitLabelBackground': '#bbbbbb',
'commitLabelColor': '#ffffff'
} } }%%
gitGraph
commit id: "4-ff6b"
commit id: "0-fd7f"
commit id: "fea 1.a"
commit id: "fea 1.b"
commit id: "fea 1.c"
commit id: "fea 1.d"
commit id: "5-af6f"
My advice is that all development is done in branches that are merged into main when completed:
%%{init: {'theme': 'dark',
'gitGraph': {'rotateCommitLabel': true},
'themeVariables': {
'commitLabelBackground': '#bbbbbb',
'commitLabelColor': '#ffffff'
} } }%%
gitGraph
commit id: "4-ff6b"
commit id: "0-fd7f"
branch feature
commit id: "fea 1.a"
commit id: "fea 1.b"
commit id: "fea 1.c"
commit id: "fea 1.d"
checkout main
merge feature
commit id: "5-af6f"
git branch <branchname>- Creates new branch branchname from current point
git checkout <branchname>- move to branch branchname
- Updates local files - beware
git merge <branchname>- Tie the branchname branch into the current checked out branch with a merge commit.1
Branches
This comes into its own when working concurrently on different features.
git is not just about backups – it is about project organisation.
This way danger and obscurity lies:
%%{init: {'theme': 'dark',
'gitGraph': {'rotateCommitLabel': true},
'themeVariables': {
'commitLabelBackground': '#bbbbbb',
'commitLabelColor': '#ffffff'
} } }%%
gitGraph
commit id: "4-ff6b"
commit id: "0-fd7f"
commit id: "fea 1.a"
commit id: "fea 1.b"
commit id: "fea 2.a"
commit id: "fea 1.c"
commit id: "fea 2.b"
commit id: "5-af6f"
commit id: "1-ad4e"
This is manageable and understandable:
%%{init: {'theme': 'dark',
'gitGraph': {'rotateCommitLabel': true},
'themeVariables': {
'commitLabelBackground': '#bbbbbb',
'commitLabelColor': '#ffffff'
} } }%%
gitGraph
commit id: "4-ff6b"
commit id: "0-fd7f"
branch feature_1
commit id: "fea 1.a"
commit id: "fea 1.b"
checkout main
branch feature_2
commit id: "fea 2.a"
checkout feature_1
commit id: "fea 1.c"
checkout main
merge feature_1
checkout feature_2
commit id: "fea 2.b"
checkout main
merge feature_2
commit id: "5-af6f"
commit id: "1-ad4e"
Branches
The examples so far have been quite simple, but this gives a good audiovisual example of the power of branches:
Exercise - Branches
We want to add a functions to calculate pendulum length from desired period and energy.
Create a branch and add the new length equation to
pyndulum/pendulum_equations.py.
Return to main and create another new branch to add the energy calculation.
Commit your work but don’t merge it.
Instead push it up to a remote feature branch.
Commit Messages
Merge/Pull Requests
- Another feature of GitHub/GitLab, NOT git.
Not be part of your local repository, nor follow the repo. - Provide a much friendlier, graphical way of merging different branches
compared to the command line. - Can be linked back to GitHub/GitLab issues
- A method of tracking progress
- can be opened after the first push
- a place for collaborative discussion.
An example: convection-parameterization-in-CAM/pull/44
When opening a request you should include:
- A description of what you have done
- Any points to be particularly aware of
- Checkboxes for required/ongoing tasks
Exercise - Merge/Pull requests
From the branches you pushed up in the previous exercise open a pull request either:
- back to the main branch of my repository where you forked from if in the workshop,
- into the main branch of your fork if working through at your own pace.
Code Review
Code review is not:
- just for ‘real’ software
- a chance for me to feel terrible about my code
Code review is:
- A chance to reflect on what you wrote
- A chance to spot bugs - we all make them!
- A test that someone else can understand your code
- A guard against laziness
- A method to improve quality reusability
- A chance to learn
Again, GitHub and GitLab have nice infrastructure to make this an effective and visual process.
Code Review
Anyone can conduct a code review on a public repository.
If working alone ask colleagues for help and return the favour.
Do:
- remember who the person you are reviewing is
- explain your reasons for requests
- praise good code, not just point out errors
Do not:
- impose preferences
- nitpick excessively
Exercise - Code Review
We will work through the two pull requests we opened.
If anyone here has opened a public one we will look at that, otherwise we will review my own code.
Closing
Summary
- git is not just a series of backups, it is a project management system.
- Improve your repositories:
- README.md
- LICENSE
- Use branches
- For each additional thing you work on.
- Make full use of GitHub and GitLab features:
- Issues
- Pull Requests
- Code review:
- Learn things, spot bugs, results in better code
- Improves re-useability
Closing
Where can I get help?
ICCS runs Climate Code Clinics that can be booked by any researcher in climate science or related fields at any time.
Apply online for a 1hr slot where 2 ICCS RSEs will sit down to take a look at your code, answer your questions, and help you improve it.
Recent topics have included:
- Adding documentation to code
- Packaging and distributing code for easy installation
- Opening projects for collaboration and project management
- Structuring ML projects
- Linking machine learning to Fortran
- Adding MPI and OpenMP to code
- …
Where can I learn more?
- References and links in these slides
- Writing Clean Scientific Software Webinar (Murphy 2023)
- Code Refinery - in particular their videos
- Good Enough Practices in Scientific Computing (wilson2017good?)
- Cambridge RSE Seminars
- Weekly presentations in West Cambridge
- rse.group.cam.ac.uk
- RSE/NCAR-HPC/other slack workspaces
Where can I learn more?
Get in touch:
References
Evans, J. 2024. “Do We Think of Git Commits as Diffs, Snapshots, and/or Histories?” https://jvns.ca/blog/2024/01/05/do-we-think-of-git-commits-as-diffs--snapshots--or-histories/.
Mukerjee, A. 2024. “Unpacking Git Packfiles.” https://codewords.recurse.com/issues/three/unpacking-git-packfiles.
Murphy, N. 2023. “Writing Clean Scientific Software.” In. Presented at the HPC Best Practices Webinar Series. https://www.youtube.com/watch?v=Q6Ksu_uX3bc.
